- Tham gia
- 3/7/07
- Bài viết
- 4,946
- Được thích
- 23,206
- Nghề nghiệp
- Dạy đàn piano
Hàm Phân phối xác suất
Hàm NORMINV()
Trả về nghịch đảo của phân phối tích lũy chuẩn.
Hàm NORMINV()
Trả về nghịch đảo của phân phối tích lũy chuẩn.
Cú pháp: = NORMINV(probability, mean, standard_dev)
Lưu ý:
Ví dụ:
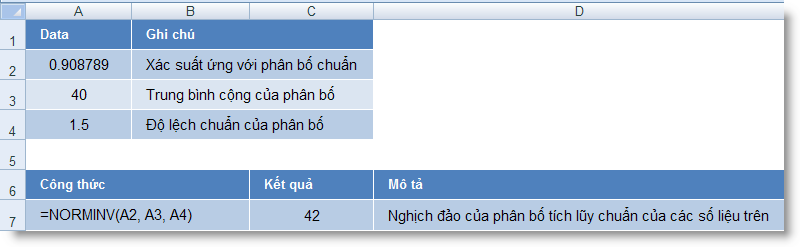
probability : Xác suất ứng với phân phối chuẩn
mean : Giá trị trung bình cộng của phân phối
standard_dev : Độ lệch chuẩn của phân phối
Lưu ý:
- Nếu có bất kỳ đối số nào không phải là số, NORMINV() sẽ báo lỗi #VALUE!
- Nếu probability nhỏ hơn 0 hoặc lớn hơn 1, NORMINV() sẽ báo lỗi #NUM!
- Nếu standard_dev nhỏ hơn hoặc bằng 0, NORMDINV() sẽ báo lỗi #NUM!
- Nếu mean = 0 và standard_dev = 1, NORMINV() sẽ dùng phân bố chuẩn.
- NORMINV() sử dụng phương pháp lặp đi lặp lại để tính hàm. Nếu NORMINV() không hội tụ sau 100 lần lặp, hàm sẽ báo lỗi #NA!
Ví dụ:
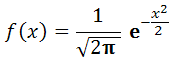
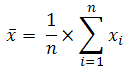
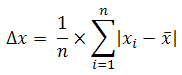

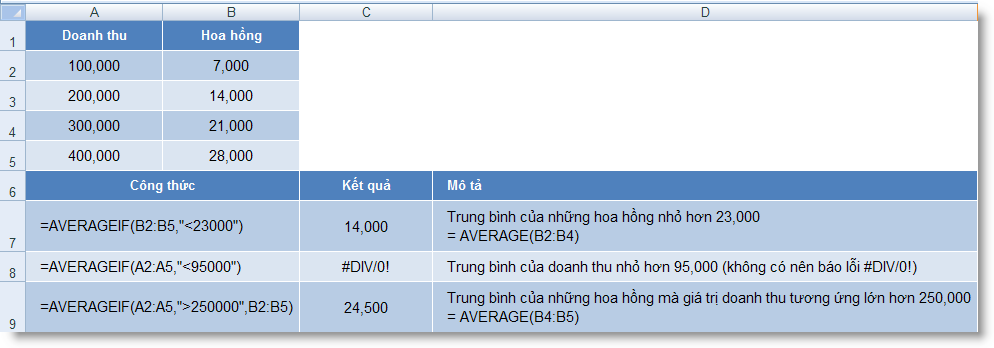
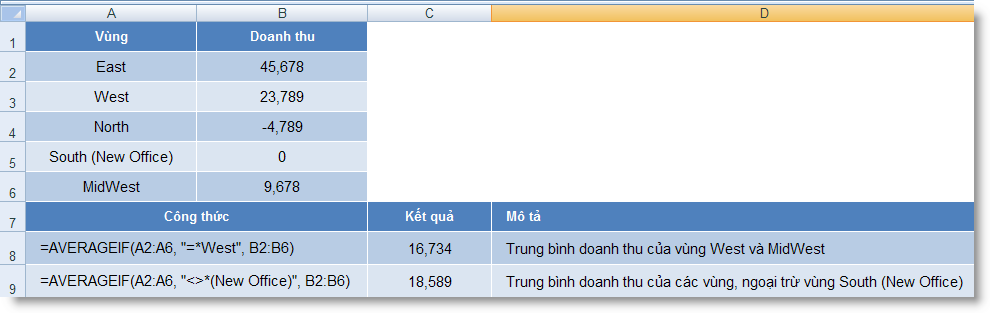
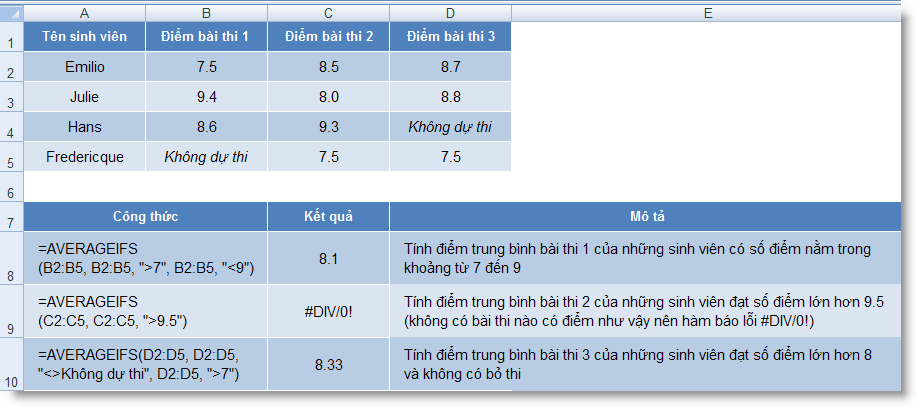
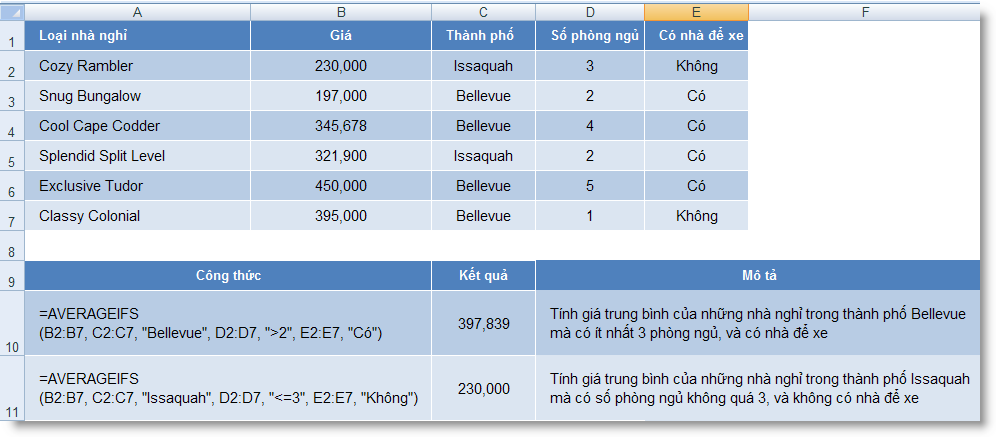
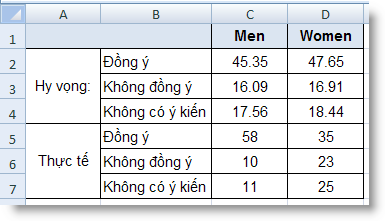
 7,C2
7,C2